Introduction to Neural Radiance Fields (NERF)

Introduction
These are my notes on the popular 2020 paper that introduced NeRF
What are NeRF used for?

Neural Radiance Fields (NeRFs) were introduced in the 2020 by MIldenhall et al to address the task of view synthesis.
Given a handful of images of a scene from different viewing directions and known camera poses, a NeRF is trained to be able to generate novel views from any new viewing position.
 The original paper showcases their performance by generating novel 2D images of the objects below in the form of videos. Watch several of these demo videos here.
The original paper showcases their performance by generating novel 2D images of the objects below in the form of videos. Watch several of these demo videos here.
 The details in the synthetic views can be remarkable accurate, as shown by the microphone textures and the water reflections in the ship.
The details in the synthetic views can be remarkable accurate, as shown by the microphone textures and the water reflections in the ship.
How do NeRFs work?

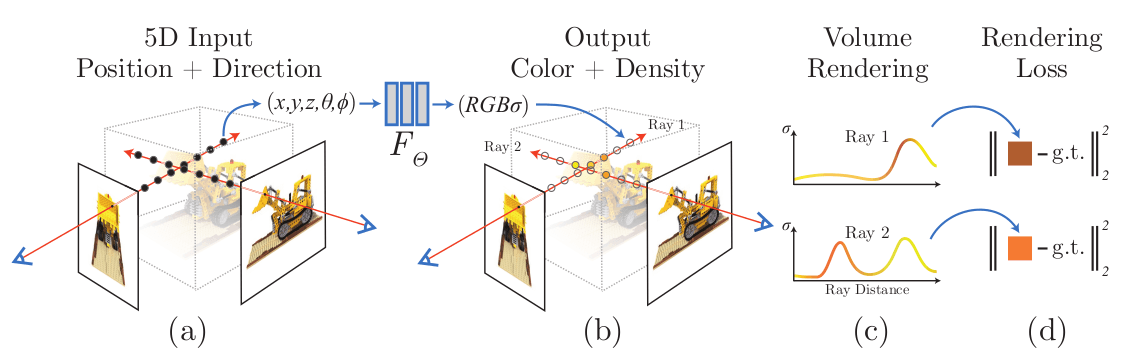
NeRFs use a neural network to learn the following mapping F:
 Given any point
Given any point (x,y,z) in the scene, F will output the color rgb and density gamma at as if that point was viewed from direction (theta, phi).
The viewing direction is important to generate realistic lighting, reflections, etc. After training F using a set of known views of a scene, we can use it to synthesize new views as follows:
- Let's imagine that
Fhas already been trained and we want to generate a 2D novel view of the scene from a given camera position.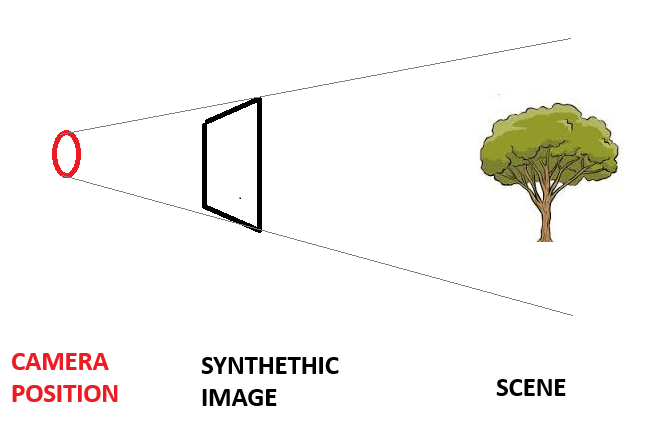
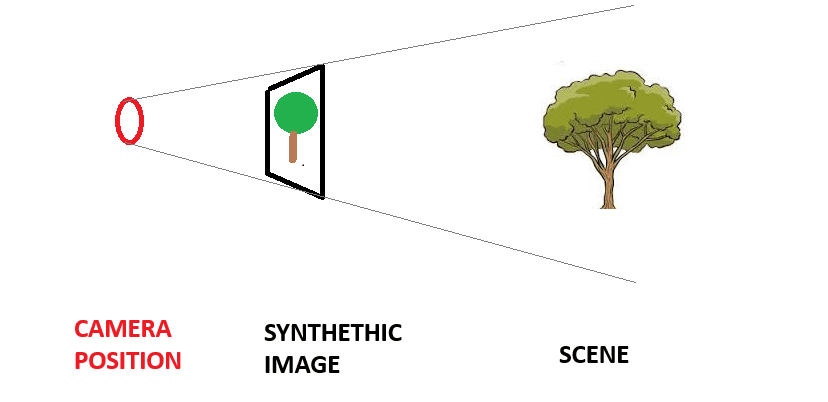
- We proceed by generating the synthetic image RGB values one pixel at a time. Let's exemplify this process with the purple pixel in the following image:
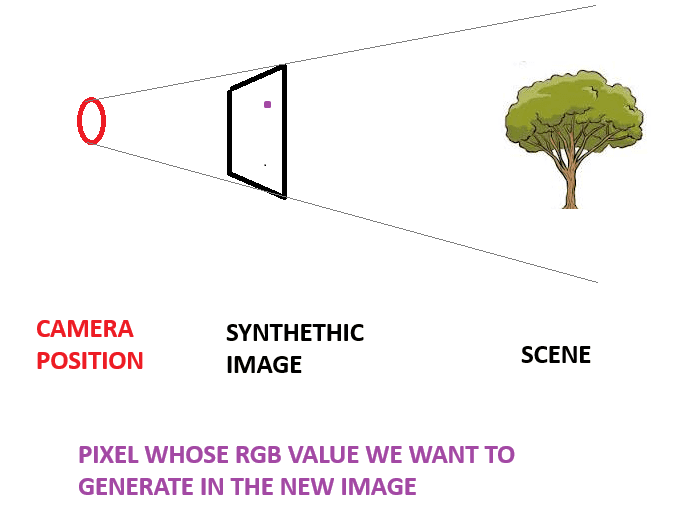
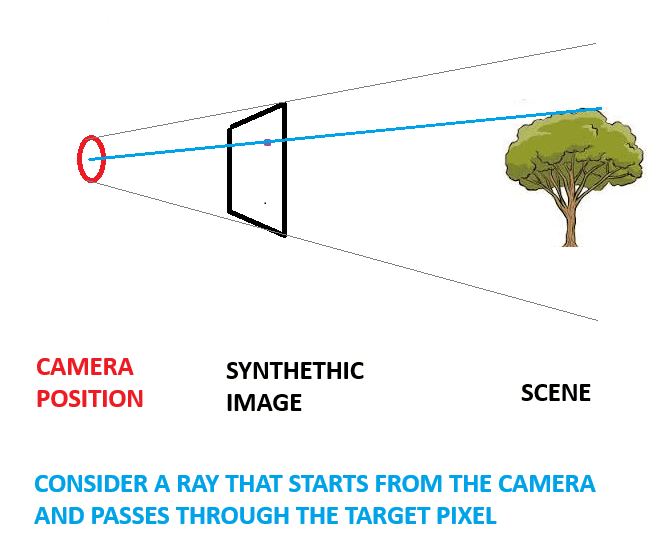
- A ray is drawn from the camera, through the pixel and into the scene
- Points are sampled along the ray and neural network
Fis evaluated on each one, outputing a density and RGB value for each sampled point.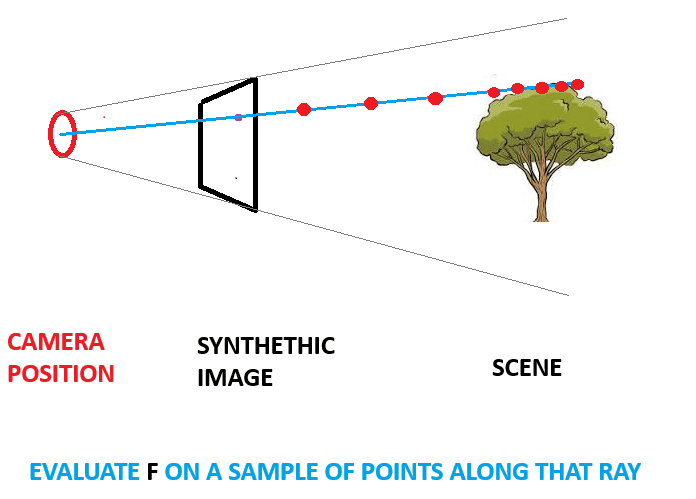
- The colors and densities are combined using volumetric rendering to generate a final RGB value that corresponds to the pixel color that we are generating in the synthetic image. We repeat this for each pixel on the synthetic image to get the novel view.
How are NeRFs trained?
In order to train the mapping F, we only have access to a training dataset of camera poses and views. This means that we do not have, a priori, a traditional set of inputs-outputs of F.
We can use the network F to sinthesize the same views that we have available for training. The pixel-wise difference in RGB values provides a differentiable loss that we can use to optimize the network by gradient descent.
Minimizing the error across different views encourages the network to produce a coherent model of the scene. After training, the scene is encoded in the weights of the neural network.
Key point: In a traditional deep learning setting, we would train a single model that would generalize to different scenes. In the NERF approach, we overfit one model for each scene. This means that there is no such thing as pretrained models or generalization to new environments ; not in the original version at least.
Neural Network Architecture
The architecture is surprisingly simple. Only fully connected layers and a skip connection, no sophisticated transformer or convolutional layers.
 Notice that:
Notice that:
- The spatial input
X=(x,y,z)is mapped to a 60-component vector via positional encoding\gamma. This is not a learned encoding, but a deterministic one using sinusoidal mappings, etc. The only purpose is to facilitate the learning process. - The network outputs the density based only on the spatial input
(x,y,z)in the second to last layer ; and it is only then that the viewing directiond(position-encoded as well) is fed to the network to produce the final RGB output.
Why are NeRFs good?
- The obvious reason is that they are very useful to create realistic new 2D views from arbitrary viewing points, or even 3D representations. This is the whole point of training a NeRF.
- Works much better than any other view synthesis techniques that preceded it.
- The scene is encoded in the NN weights, which is a way around prohibitive costs of discretized voxel cells.
- Considers the viewing direction → Handle reflections, shadows, etc.
After the original 2020 paper, which for machine learning standards is ancient by now, many follow up works advanced the field:
- Efficiency improvements, some implementation allowing even real-time rendering speeds.
- Enhanced realism
- Extend to 3D reconstruction, video, augmented reality
Metrics
Evaluating the quality of a Neural Radiance Field (NeRF) reconstruction typically involves measuring how well the rendered views match the ground truth views. Common metrics are:
-
Peak Signal-to-Noise Ratio (PSNR)
- Measures the similarity between the rendered and ground truth images.
- Higher PSNR indicates better reconstruction quality.
-
Structural Similarity Index Measure (SSIM)
- Evaluates perceptual similarity, focusing on structural information in the images.
- Values range from 0 to 1, with 1 being a perfect match.
-
Mean Squared Error (MSE)
- Quantifies pixel-wise differences between rendered and ground truth images.
- Lower MSE indicates better reconstruction.
-
Learned Perceptual Image Patch Similarity (LPIPS)
- Measures perceptual differences using features extracted from a deep neural network.
- Lower LPIPS scores indicate better perceptual quality.
-
Rendering Speed and Efficiency
- Evaluates the time taken to generate a single view.
- Important for real-time or practical applications.
-
Novel View Synthesis Accuracy
- Tests how accurately NeRF renders unseen viewpoints by comparing to withheld validation images.
IMO, metrics cannot replace visual Inspection , especially for evaluating geometric consistency, artifacts, and texture quality in rendered scenes.